
In today’s fast-evolving cybersecurity landscape, organizations face an increasing number of threats targeting their digital assets. Offensive Security Assessment plays a critical role in safeguarding these assets by proactively identifying and addressing vulnerabilities before attackers can exploit them. This method simulates real-world attack scenarios to test and enhance an organization’s security defenses.
What is an Offensive Security Assessment?
Offensive Security Assessment is a hands-on approach to evaluating an organization’s security posture by mimicking the behavior of malicious attackers. By simulating multi-stage attacks, this technique identifies potential vulnerabilities and explores how an attacker might exploit them. It assumes an attacker has already gained initial access to the system and examines how they could escalate privileges, move laterally within the Cloud, exfiltrate sensitive data, or disrupt operations.
Offensive, Defensive, and Purple Teaming Insights
| Aspect | Offensive Security | Defensive Security | Purple Teaming |
| Definition | Proactively identifies vulnerabilities by simulating attacks. | Protects Infrastructure by implementing and maintaining security measures. | Combines offensive and defensive approaches for collaborative security enhancement. |
| Core Principle | “Think like an attacker” to find the exploitable weaknesses. | “Think like a defender” to prevent, detect, and respond to threats. | “Collaborate and adapt” to integrate offensive insights with defensive strategies. |
| Key Activities | Penetration testing, red teaming, adversary emulation. | Deploying SIEM, intrusion detection systems (IDS), and threat hunting. | Joint exercises, feedback loops, real-world attack emulation, improving defences. |
| Mindset | Focuses on breaking in to expose vulnerabilities. | Focuses on safeguarding assets from potential attacks | Focuses on teamwork and knowledge sharing between offensive and defensive teams |
| Goal | Strengthen systems by uncovering and remediating flaws. | Security analysts, blue team members, SOC engineers, system administrators. | Collaboration between red and blue teams, often guided by purple team facilitators. |
| Focus Area | Proactively testing resilience against simulated attacks. | Ensuring Infrastructure integrity through monitoring, threat detection, and incident management. | Enhancing both offensive and defensive capabilities through seamless coordination and shared objectives. |
| Tools and Technique | Exploit frameworks, attack simulations, vulnerability scanners, social engineering. | Firewalls, SIEM tools, EDR, threat intelligence platforms, incident response plans. | Integration of offensive and defensive tools; joint analysis of simulated attacks and incident handling. |
Elevate Your Offensive Security Assessment: Proactive Strategies for Modern Threats
In today’s complex Infrastructure, understanding and addressing vulnerabilities is critical to safeguarding your assets. This guide walks you through key strategies to strengthen your cloud security posture by combining offensive, defensive, and collaborative approaches.
Detect Critical Gaps in Your Infrastructure
Assess the infrastructure to determine the blast radius and evaluate the potential impact of security misconfigurations. By prioritizing mitigation strategies based on the highest risks, you can proactively strengthen your defenses and focus on the most critical areas for improvement.
Identify Rogue Access in Your Cloud Environment
Detect accounts, users, and groups with unnecessary or elevated privileges to sensitive information. By analyzing cloud permissions, you can minimize the attack surface and enforce least privilege principles.
Elevate Your Security with Collaborative Purple Teaming
Leverage the power of Purple Teaming to enhance your defenses:
- Collaborative Assessments: Work alongside experts to simulate real-world attack scenarios based on findings from offensive security assessments.
- Enhanced Visibility: Integrate missing log sources into Coralogix for comprehensive monitoring and detection.
- Custom Recommendations: Build tailored strategies to detect and respond to threats, enhancing your overall alerting capabilities.
Full Flexibility for Custom Attack Scenarios
Test your cloud infrastructure under tailored conditions, focusing on your specific threat landscape. Whether targeting insider threats, unauthorized access, or lateral movement, the flexibility ensures the assessment aligns with your business objectives.
Simulating Real-World Attack Scenarios with Operational Safeguards
Demonstrate how skilled adversaries could exploit vulnerabilities in your cloud environment, all while maintaining operational integrity.
Our safeguards include:
- No Service Disruption: Ensuring uninterrupted operations throughout the assessment.
- Data Integrity: No deletion or modification of existing data.
- Configuration Preservation: Retaining current system configurations during testing.
These safeguards allow for a realistic yet safe assessment of your defenses, preparing your team to detect and respond to advanced threats without risk to your business continuity.
Why Snowbit for Offensive Security?
At Snowbit, we go beyond traditional security assessments. Our Offensive Security Assessment helps customers identify custom attack paths unique to their infrastructure—paths that could be exploited by adversaries. By leveraging cutting-edge techniques, our managed security services team simulates real-world attack scenarios to uncover vulnerabilities and hidden risks.
Turn Insights Into Actionable Alerts
Following each assessment, our research team develops tailored alerts for every identified attack path, ensuring continuous monitoring and proactive defense. These alerts are integrated directly into the Coralogix SIEM platform, giving customers unparalleled visibility and actionable intelligence to safeguard their cloud environments.
Case Study:
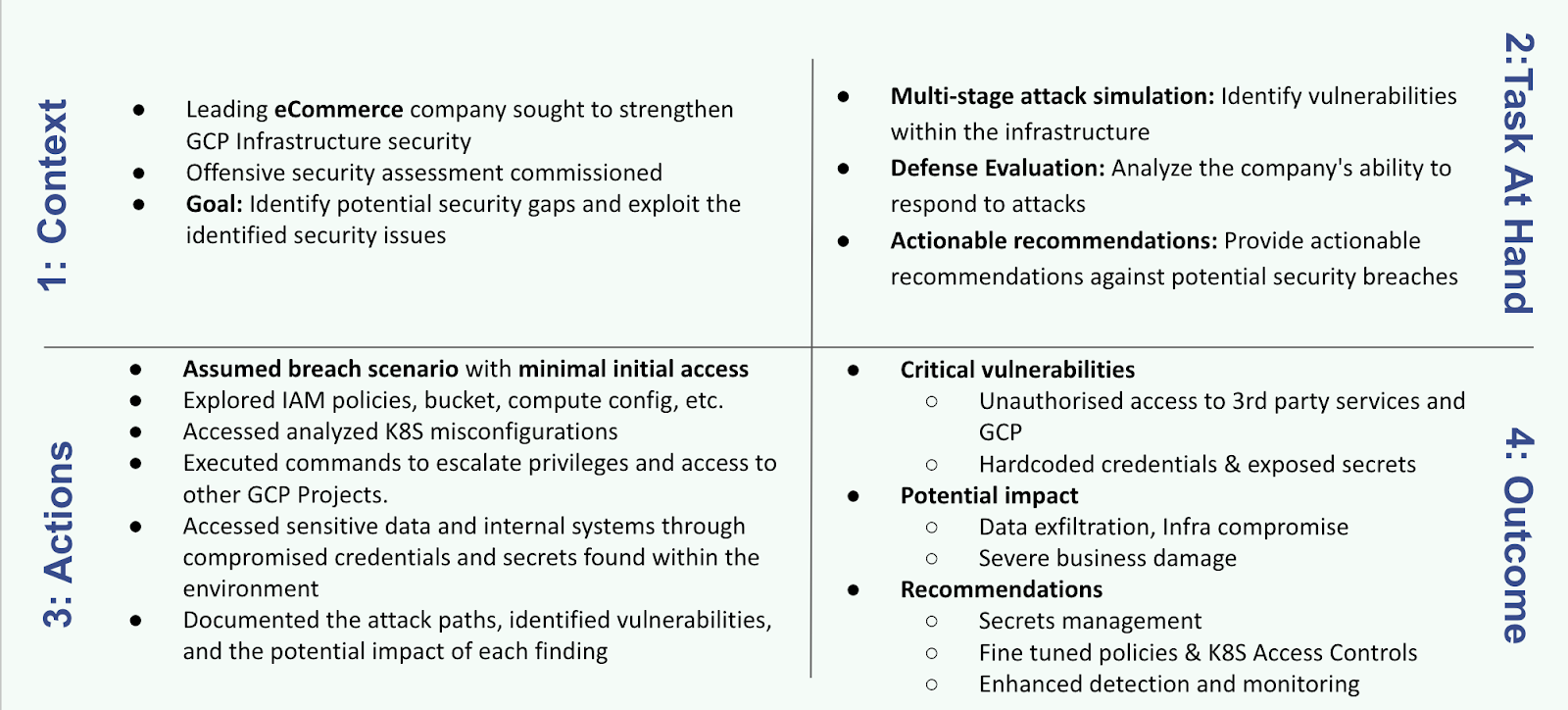
GCP Offensive Security Assessment
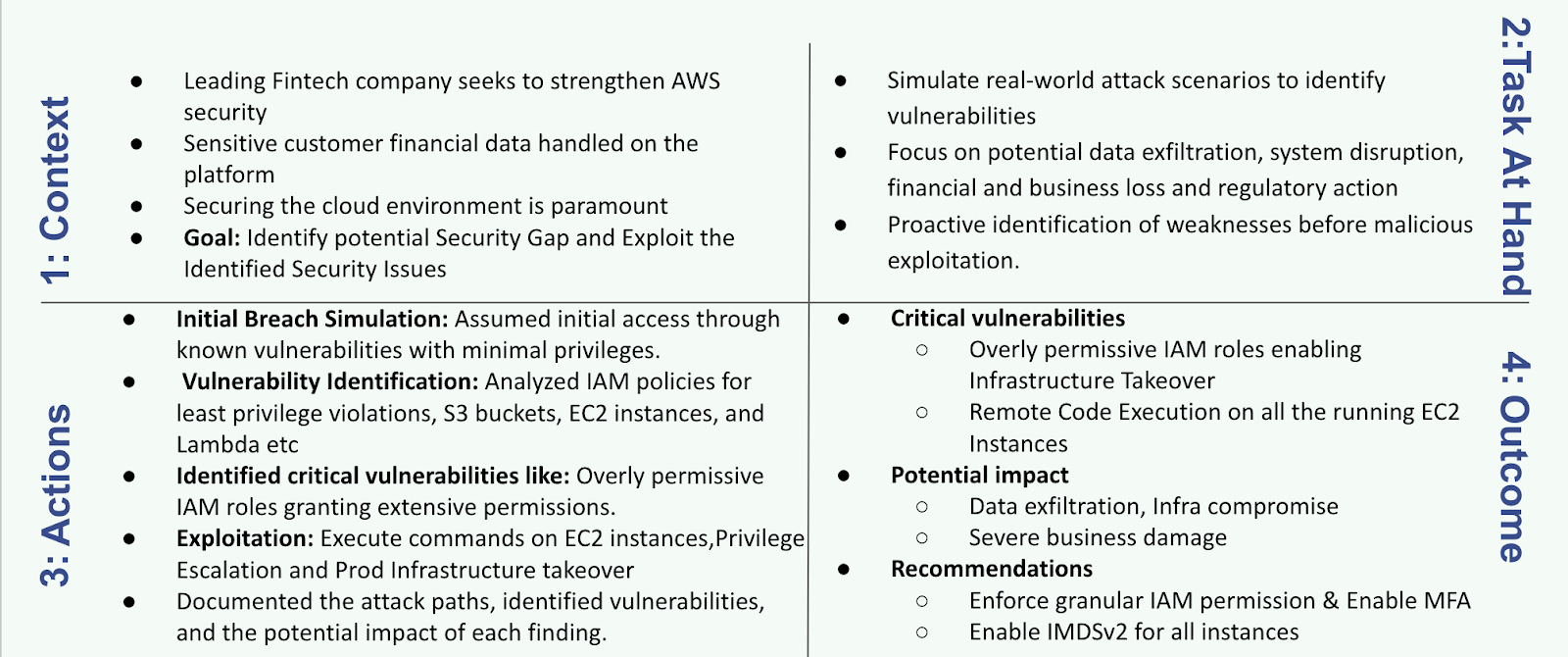
AWS Offensive Security Assessment
Learn more about Coralogix security offerings today
Using VPC Flow Logs to Monitor and Optimize Your Network TrafficAmazon Virtual Private Cloud (VPC) Flow Logs is a feature provided by AWS (Amazon Web Services) that allows you to capture information about the IP traffic going to and from network interfaces in your VPC. It provides detailed information about the traffic within your VPC, including information such as source and destination IP addresses, ports, protocol, and the amount of data transferred.
VPC Flow logs capture information that provide visibility into network traffic for monitoring, troubleshooting security and performance, and optimizing resource utilization. The information captured includes:
- Source and destination IP addresses and ports
- Protocol (TCP, UDP, ICMP)
- Number of packets and bytes
- Start and end time of flows
- Whether the traffic was accepted or rejected
VPC Flow logs do not capture payload data or real-time traffic; data is aggregated over 10 seconds or longer intervals before being published to CloudWatch Logs, S3, or Kinesis Firehose.
Decoding and Understanding AWS VPC Flow Logs
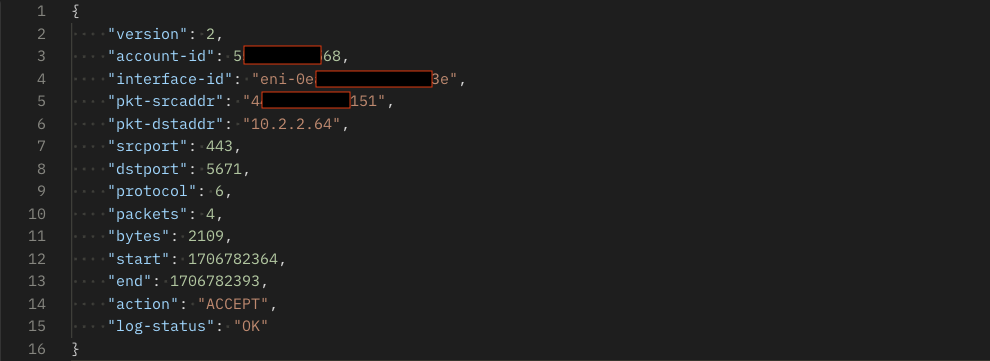
It’s essential to understand what each field captured in a VPC flow log means, in order to analyze and troubleshoot your VPC network traffic effectively. Here’s a quick overview:
Default Fields

VPC flow logs contain the following default fields:
- version: The VPC flow logs version used
- account-id: The AWS account ID that owns the interface
- interface-id: The ID of the elastic network interface (ENI) where traffic is recorded
- srcaddr: The source IP address
- dstaddr: The destination IP address
- srcport: The source port number
- dstport: The destination port number
- protocol: The protocol (TCP, UDP, ICMP, and etc.)
- packets: The number of packets in the flow
- bytes: The number of bytes in the flow
- start: The time the flow started
- end: The time the flow ended
- action: Whether traffic was accepted or rejected
- log-status: Logging completion status
Additional Fields
You can enable further metadata like:
- VPC ID: ID of the VPC containing the interface
- Subnet ID: ID of the subnet containing the interface
- Instance ID: ID of the EC2 instance containing the interface
- TCP flags: TCP flags seen on the flow (SYN, ACK, etc.)
- Type: Type of flow (IPv4 or IPv6)
- Packet loss: Percentage of lost packets
These fields can provide more context for the recorded flows.
Analyzing the comprehensive flow log data enables deep network visibility for monitoring, troubleshooting, and optimization.
Key Benefits of Enabling VPC Flow Logs
VPC Flow Logs can help with:
- Network monitoring: Analyze traffic patterns, identify anomalous flows, and optimize performance.
- Troubleshooting: Diagnose connectivity and latency issues and ACL misconfigurations.
- Security analysis: Detect suspicious traffic, unauthorized access attempts, and DDoS patterns.
- Cost optimization: Identify unnecessary traffic across regions/VPCs to reduce data transfer costs.
Enabling VPC Flow Logs
You can enable flow logs at the VPC, subnet, or network interface level. Flow logs can be published to CloudWatch Logs, S3, or Kinesis Firehose.
To enable, you specify the resources to monitor and the destination via AWS Console, CLI, or API calls. You can also configure sampling rate, aggregation interval, and filters.
Using the AWS Management Console
- Open the Amazon VPC Console and navigate to “Flow Logs” in the left sidebar
- Click “Create Flow Log”
- Specify the resources to monitor by choosing VPCs, Subnets, or Network Interfaces
- Select the destination for logs – CloudWatch Logs, S3 bucket, or Kinesis Data Firehose
- Set additional parameters like log format, filters, or aggregation interval
- Click “Create”
Using AWS CLI
Below is a sample CLI command to create a flow log:
aws ec2 create-flow-logs –resource-ids vpc-111bbb222 –resource-type VPC –traffic-type ALL –log-destination-type cloud-watch-logs
Using CloudFormation Template
You can specify a flow log resource in your AWS CloudFormation template as below:
Resources:
VPCFlowLog:
Type: AWS::EC2::FlowLog
Properties:
ResourceType: VPC
ResourceId: vpc-12abc34df5
TrafficType: ALL
LogDestinationType: cloud-watch-logs
LogDestination: !Ref LogsGroup
LogFormat: ${version} ${vpc-id}
This allows flow log creation to be automated as part of stack deployments.
The key is choosing the right resources for monitoring, log destinations, and traffic filters based on your specific use cases.
Enhanced Visibility with Coralogix
Sending your VPC Flow Logs to Coralogix provides greater visibility with:
- Log parsing and indexing to make logs searchable and easier to analyze
- Anomaly detection to spot abnormal traffic patterns
- Root cause analysis to correlate network issues with other log types inside a VPC
- Traffic pattern analysis over time to understand growth and changes
Coralogix integrates seamlessly with AWS services to ingest flow logs data and provides a powerful query language and visualization tools for insights.
You can read more about how to set up VPC flow logs delivery to S3 for streaming via lambda to Coralogix here.
Coralogix security offering provides a comprehensive set of out-of-the-box detections & alerts for AWS VPC Flow Logs. Some of the notable ones include:
Alerts
Here are some examples of the out-of-the-box alerts customers can deploy to their platform with 1-click.
- Non-Standard DNS Protocol Activity
- Scope: This alert triggers when DNS queries from internal hosts use TCP port 53 instead of the standard UDP. While TCP over port 53 can be legitimate for zone transfers or to accommodate large packets, it can also indicate suspicious activities such as tunneling or attempts to bypass security controls.
- Potential Impact: Non-standard DNS protocol activity could indicate malicious behavior, such as data exfiltration or command and control communication. It may lead to unauthorized access to resources, data breaches, or the introduction of malware into the network.
- Remediation Recommendation:
- Investigate: Immediately investigate the source and destination of the DNS traffic using TCP port 53. Determine if it aligns with legitimate activities such as zone transfers or if it indicates malicious behavior.
- Monitor: Continuously monitor DNS traffic for similar anomalies. Implement alerting mechanisms to promptly identify and respond to any deviations from normal behavior.
- Restrict Traffic: Enforce strict egress filtering rules to only allow DNS traffic over UDP port 53. Consider implementing DNS security solutions that can detect and mitigate suspicious DNS activities.
- Educate Users: Educate internal users about the risks associated with non-standard DNS protocol activities and the importance of adhering to security policies and best practices.
- Incoming Connections Over Remote Service Ports
- Scope: This alert triggers when an incoming SSH (port 22) or RDP (port 3389) connection is accepted. These ports enable remote command line and desktop access, posing a security risk if unauthorized.
- Potential Impact: Unauthorized incoming SSH or RDP connections can lead to unauthorized access to sensitive systems, data breaches, or the execution of malicious activities such as privilege escalation or data theft.
- Remediation Recommendation:
- Review Access Controls: Review and strengthen access controls to restrict SSH and RDP access only to authorized users and IP addresses.
- Implement Multi-Factor Authentication (MFA): Require the use of MFA for SSH and RDP authentication to add an extra layer of security.
- Monitor and Audit: Continuously monitor incoming SSH and RDP connections for unauthorized access attempts. Enable detailed logging and auditing to track user activities and detect suspicious behavior.
- Network Segmentation: Implement network segmentation to isolate critical systems from less secure environments, reducing the impact of potential security breaches.
- Update and Patch Systems: Ensure that SSH and RDP servers are regularly updated with the latest security patches to mitigate known vulnerabilities.
- Excessive Inbound ICMP Traffic
- Scope: This alert triggers whenever an IP address sends many ICMP ping requests to hosts within a VPC within a short interval.
- Potential Impact: Excessive inbound ICMP traffic can potentially be used in ICMP flood attacks, causing network congestion, service disruption, or denial of service (DoS) to the affected hosts.
- Remediation Recommendation:
- Implement Rate Limiting: Configure rate-limiting mechanisms to limit the number of ICMP requests allowed per second, mitigating the impact of ICMP flood attacks.
- Block Suspicious IPs: Identify and block IP addresses generating excessive ICMP traffic, especially those exhibiting patterns indicative of malicious intent.
- Network Intrusion Detection/Prevention Systems (NIDS/NIPS): Deploy NIDS/NIPS solutions to detect and block ICMP flood attacks in real-time.
- Traffic Shaping: Implement traffic shaping techniques to prioritize legitimate traffic and mitigate the impact of ICMP floods on network performance.
- Update Security Policies: Regularly review and update security policies to adapt to emerging threats and vulnerabilities, including ICMP flood attacks.
Dashboards
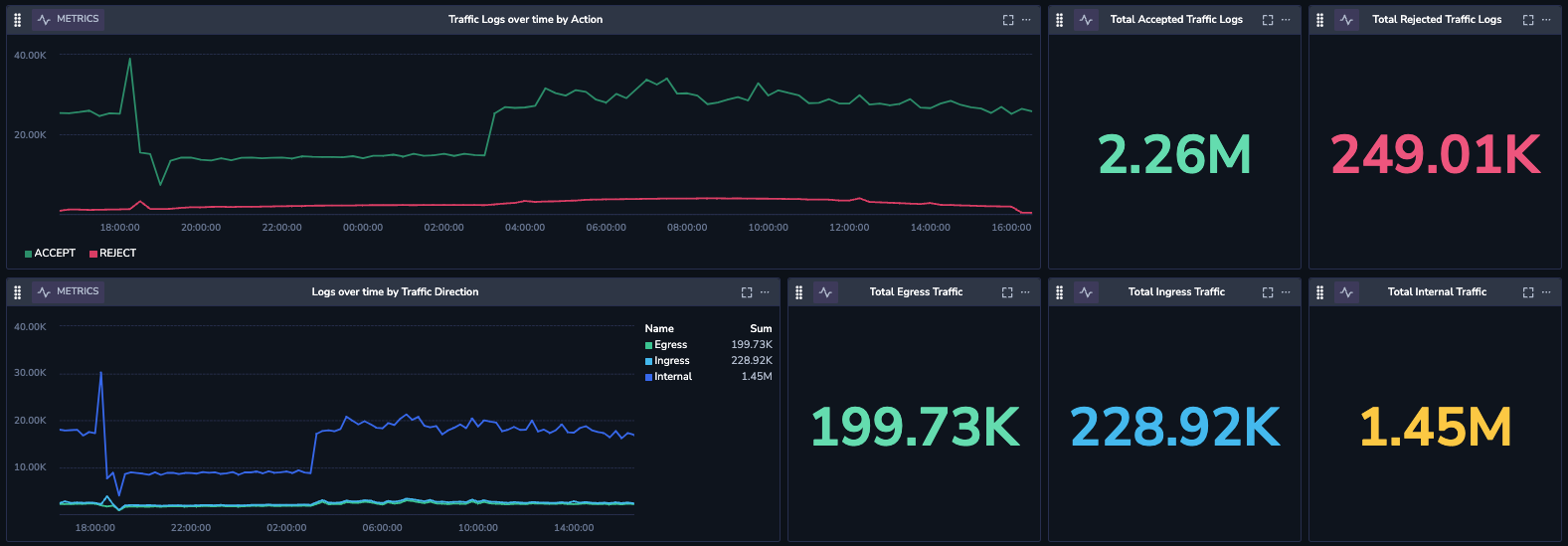
Using Coralogix Security, out-of-box insights can be deployed to understand various metrics. Some of the examples include –
- Total Accepted/Rejected traffic
- Total Egress traffic
- Distribution of top source countries over time
- Top source IPs
- Top destination IPs etc.
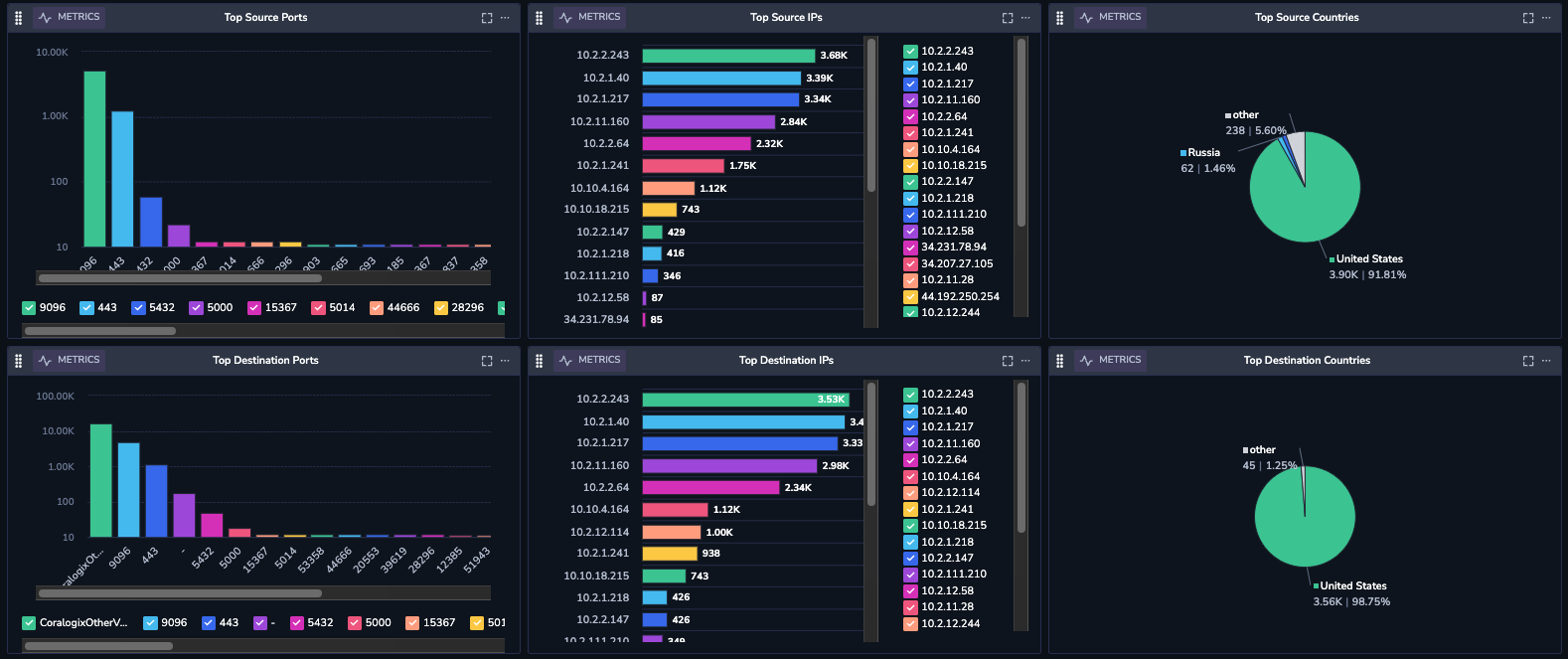
Optimization Based on Insights
By leveraging the deeper visibility provided by VPC Flow Logs analytics with Coralogix, you can:
- Detect and troubleshoot sub-optimal network routes faster
- Identify unnecessary cross-region/VPC traffic to minimize costs
- Inform security group and NACL rules optimization
- Plan for scaling needs proactively based on growth trends
VPC Flow Logs + Coralogix provides the comprehensive visibility and analytics capabilities needed to master observability across cloud-native applications and dynamic AWS network environments.
Conclusion
As we have seen, VPC flow logs are essential to the Security Monitoring arsenal. By sending AWS VPC flow logs to Coralogix, organizations can unlock further value through integrated log analytics and security capabilities. Coralogix enables faster searching through parsing and indexing and customizable dashboards and alerts tailored to the environment that provide security teams early warning across operations, security, and business metrics extracted from the flow logs.
Learn more about Coralogix security offerings today.
Amazon Route53: Best practices, security monitoring use casesAmazon Route53
Amazon Route53 is a highly available and scalable Domain Name System (DNS) web service provided by Amazon Web Services (AWS). Its primary purpose is to enable users to route internet traffic to their resources, such as websites, web applications, and APIs, while offering domain registration, DNS routing, and health-checking capabilities.
It is designed to deliver fast and reliable connections to internet applications running on AWS or on-premises systems. It uses a global network of servers to answer DNS queries and maintains high availability through redundant controls and data planes.
Users can leverage this service to build complex routing relationships, set up both public and private hosted zones, and implement health checks to ensure application availability.
Here is a brief visual overview, including logs, best practices, detections, and the security value we will discuss in this post:
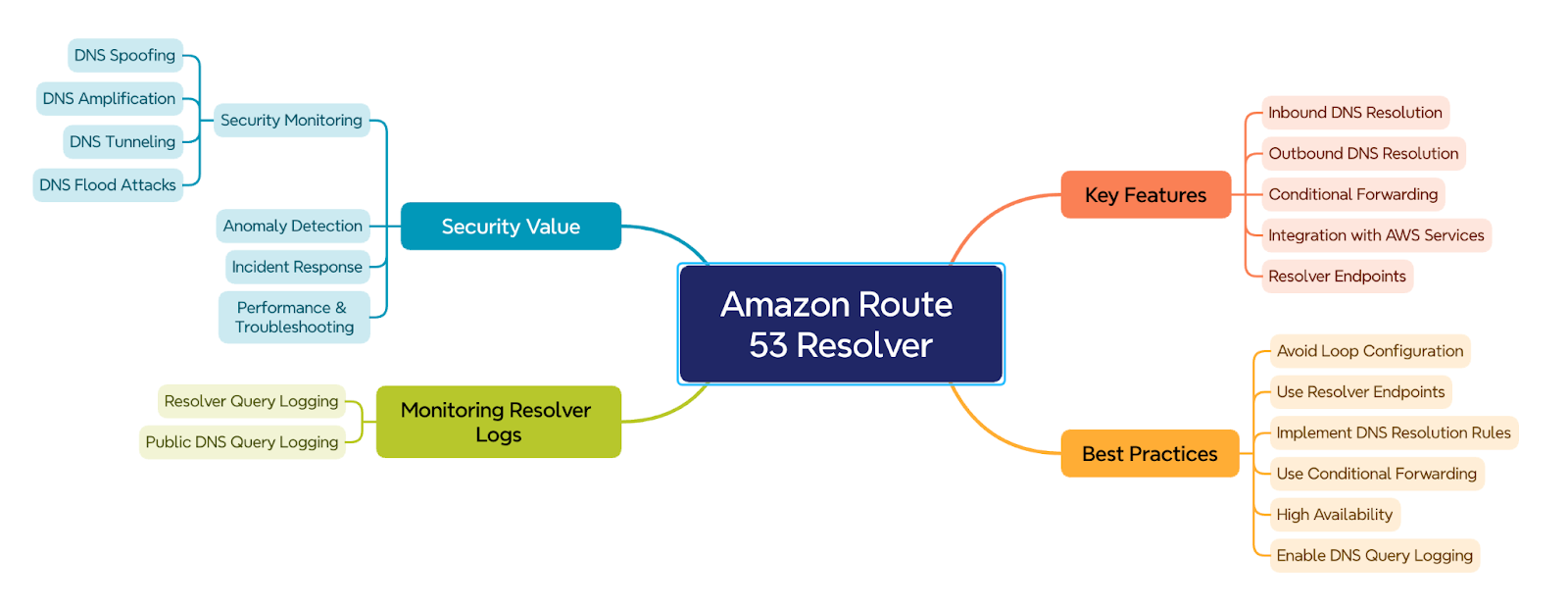
Amazon Route53 Resolver
It is a component that facilitates DNS query resolution across AWS, the internet, and on-premises networks with secure control over Amazon Virtual Private Cloud (VPC) DNS.
Here are some key features and functionalities:
- Inbound DNS Resolution – Resolve DNS queries originating from your VPCs to outside, such as public internet or other AWS services within the same account. Receive recursive DNS resolution for your VPCs, allowing them to resolve public domain names or private domain names within your AWS environment.
- Outbound DNS Resolution – Resolve DNS queries originating from your on-premises network to resources within your VPCs. It acts as a resolver for your on-premises DNS servers, allowing them to resolve private domain names hosted in your AWS environment.
- Resolver Endpoints – Use resolver endpoints deployed within your VPCs to handle DNS queries. These endpoints can be configured to forward DNS queries to designated DNS resolvers in your on-premises network or to use Route53 Resolver’s built-in recursive DNS resolvers for outbound resolution.
- Conditional Forwarding – Implement conditional forwarding rules, allowing you to direct DNS queries for specific domain names or subdomains to designated DNS resolvers in your on-premises network.
- Integration with AWS Services – Seamless integration with other AWS services, such as Amazon VPC, AWS Directory Service, and AWS Transit Gateway, to provide secure and reliable DNS resolution across hybrid cloud environments.
For more detailed guidance on setting up and utilizing resolver, refer to the AWS documentation.
Best Practices for Route53 Resolver
- Avoid Loop Configurations – Do not associate the same VPC to a Resolver rule and its inbound endpoint, especially if they share a common VPC, or else risk entering loops where queries are continuously passed back and forth without reaching the intended destinations.
- Use Resolver Endpoints – Simplify DNS management and reduce administrative overhead.
- Implement DNS Resolution Rules – Route traffic to specific DNS resolvers based on domain names or IP addresses, enabling granular control over DNS resolution.
- Use Conditional Forwarding – Configure conditional forwarding rules to direct DNS queries for specific domains or subdomains to designated DNS servers in your on-premises network. This allows you to maintain centralized control over DNS resolution for your organization’s internal domains while leveraging Route53 Resolver for other DNS queries.
- High Availability – When creating your Route 53 Resolver inbound endpoints, ensure to create at least two IP addresses that the DNS resolvers on your network will forward queries to. It is also recommended to specify IP addresses in at least two Availability Zones for redundancy.
- Security Measures – Configure DNS firewall rules to block or allow DNS queries based on predefined criteria, such as domain names, IP addresses, or query types. This helps protect your network from DNS-based attacks, such as malware infections, data exfiltration, or command-and-control communication. Also, use DNS over HTTPS (DoH) or DNS over TLS (DoT) to encrypt DNS queries and responses, preventing eavesdropping and tampering by attackers.
- Enable DNS Query Logging – Troubleshoot DNS-related issues, detect malicious activity, and comply with regulatory requirements.
For more detailed guidance on best practices, refer to the AWS documentation.
Monitoring Route53 Resolver Logs
Monitoring is an important part of maintaining the reliability, availability, and performance of your AWS solutions. To monitor resolver logs, you can enable query logging, which records all DNS queries that your resolver handles. Optimize the performance and reliability of your DNS resolution and ensure compliance with relevant regulations.
Resolver Query Logging
AWS Route53 Resolver query logging allows you to monitor DNS queries originating from Amazon Virtual Private Cloud (VPC) environments and on-premises resources connected via Resolver endpoints. By configuring query logging, you can gain insight into the following types of queries:
- Queries initiated within specific VPCs
- Queries from on-premises resources using inbound Resolver endpoints
- Queries using outbound Resolver endpoints for recursive DNS resolution
- Queries involving Route53 Resolver DNS Firewall rules
Resolved queries are logged with information such as the AWS Region, VPC ID, source IP address, instance ID, query name, DNS record type, response code, and response data. Logged queries are sent to one of the following AWS resources:
- Amazon CloudWatch Logs
- Amazon Simple Storage Service (S3)
- Amazon Kinesis Data Firehose
Please see here for more details.
Public DNS Query Logging
Amazon Route53 provides DNS query logging capabilities that allow you to monitor and log information about the public DNS queries received by Route53. These logs provide insights into the following:
- Domain or subdomain requested
- Date and time of the request
- DNS record type (e.g., A or AAAA)
- Route53 edge location that responded to the DNS query
- DNS response code, such as “NoError” or “ServFail”
Once you configure query logging, Route53 sends logs to Amazon CloudWatch Logs, where you can access and analyze them. This is particularly helpful for security analysis, troubleshooting, compliance auditing, and gaining insights into DNS query patterns.
Please see here for more details.
Please note that AWS Route53 Resolver query logging does not incur any additional charges apart from the fees for the selected destination service, such as Amazon CloudWatch Logs, Amazon Simple Storage Service (S3), or Amazon Kinesis Data Firehose.
Security Monitoring Use Cases
The security value of AWS Route53 Resolver logs is quite significant. By enabling Resolver logging, you gain visibility into the DNS query activity within your infrastructure, along with:
- Security Monitoring Of DNS Specific Attacks – Detect and investigate suspicious or unauthorized DNS activity. By analyzing DNS query logs, you can identify potential indicators of compromise, such as unusual query patterns, unauthorized domain resolutions, or attempts to access malicious domains. Here are some examples of potential attacks on AWS Route53 Resolver:
- DNS Spoofing or Cache Poisoning – Attackers may attempt to poison the DNS cache of Route53 Resolver by sending forged DNS responses containing incorrect or malicious IP addresses for legitimate domain names. This can lead to users being directed to attacker-controlled servers, enabling various forms of attacks such as phishing or malware distribution.
- DNS Amplification – Attackers may abuse Route53 Resolver’s recursive DNS capabilities to launch DNS amplification attacks. By sending large volumes of DNS queries with spoofed source IP addresses to Route53 Resolver, attackers can cause it to generate significantly larger DNS responses, amplifying the volume of traffic directed at a victim’s network, potentially leading to denial-of-service (DoS) conditions.
- DNS Tunneling – Attackers may use DNS tunneling techniques to bypass network security controls and exfiltrate data from compromised systems. By encoding data within DNS queries or responses, attackers can establish covert communication channels with external servers, allowing them to transfer sensitive information undetected by traditional security mechanisms.
- DNS Flood Attacks – Attackers may launch DNS flood attacks against Route53 Resolver by sending a high volume of bogus DNS queries or responses to overwhelm its resources and cause service disruptions. DNS flood attacks can degrade the performance of Route53 Resolver, leading to increased latency, packet loss, or even service outages.
- Anomaly Detection – Route53 Resolver logs can help you identify abnormal DNS behavior within your network. By comparing DNS query logs over time, you can detect unusual spikes in query volume, unexpected changes in DNS resolution patterns, or anomalous DNS responses that may indicate security incidents or infrastructure issues.
- Incident Response – In the event of a security incident or a potential breach, Resolver logs can provide valuable evidence for investigation. By correlating DNS query data with other security events and logs, such as firewall or endpoint logs, you can reconstruct the attack chain and identify the root cause of the incident. This helps in understanding the scope of the incident and taking appropriate remedial actions.
- Performance and Troubleshooting – Resolver logs provide insights into DNS query performance and can help in troubleshooting DNS-related issues. By monitoring query response times, error rates, and other relevant metrics, you can identify bottlenecks, misconfigurations, or connectivity issues that may impact the performance of your DNS infrastructure. This allows you to proactively address these issues and ensure optimal DNS resolution.
In summary, monitoring AWS Route53 Resolver logs is essential for security, incident response, compliance, and performance optimization. It provides valuable insights into DNS activity, helps detect and respond to threats, and ensures the smooth functioning of your DNS infrastructure.
It’s important to note that while Route53 Resolver Logs provide valuable security value, they should be used in conjunction with other security measures and best practices to ensure a comprehensive security posture for your AWS infrastructure.
Out-of-the-Box AWS Route53 Resolver Security with Snowbit by Coralogix
So far we have discussed Route53 Resolver, best practices for using it effectively, and its security value. Equally important is to have in place mechanisms to be notified in real-time of any unusual or abnormal events and/or configuration changes. Hence detective controls are needed to be in place.
Coralogix’s Snowbit security offering provides a comprehensive set of out-of-the-box detections & alerts for Route53 Resolver. Some of the notable ones include:
- Route53 audit events
- Anomalous DNS query response codes detected
- Anomalous uncommon DNS record types detected
- DNS queries to monero mining pools detected
- AWS metadata query detected
- DNS queries with Base64 encoded string detected
- Anomalous DNS activity on TCP detected
Not only are existing alerts customizable based on specific customer requirements but also any needed custom detections and dashboards can be added quickly – reducing time to value dramatically.
We would love to discuss this further with you so feel free to schedule a demo with our team.
SIEM Tutorial: What should a good SIEM Provider do for you?Modern day Security Information and Event Management (SIEM) tooling enterprise security technology combine systems together for a comprehensive view of IT security. This can be tricky, so we’ve put together a simple SIEM tutorial to help you understand what a great SIEM provider will do for you.
A SIEM’s responsibility is to collect, store, analyze, investigate and report on log and other data for incident response, forensics and regulatory compliance purposes. This SIEM tutorial will explain the technical capabilities that a SIEM provider should have.
Technical Capabilities of Modern SIEM Providers
Data collection
One of the most understood SIEM capabilities, data collection or log management, collects and stores the log files from multiple disparate hosts into a centralized location. This allows your security teams to easily access this information. Furthermore, the log management process can reformat the data it receives so that it is all consistent, making analysis less of a tedious and confusing process.
A SIEM can collect data in several ways and the most reliable methods include:
- Using an agent installed on the device to collect from
- By directly connecting to a device using a network protocol or API call
- By accessing log files directly from storage, typically in Syslog format or CEF (Common Event Format)
- Via an event streaming protocol like Netflow or SNMP
A core function of a SIEM is the ability of collecting data from multiple devices, standardizing it and saving it in a format that enables analysis.
Advanced analytics
A SIEM tool needs to analyse security data in real time time. Part of this process involves using ‘Advanced Analytics’. SIEM or ‘Next Gen SIEM’ tools of today, have been extending their capabilities to more frequently include analytics functions. These automated analytics run in the background to proactively identify possible security breaches within businesses’ systems. An effective SIEM provides advanced analytics by using statistics, descriptive and predictive data mining, machine learning, simulation and optimization. Together they produce additional critical insights. Key advanced analytics methods include anomaly detection, peer group profiling and entity relationship modeling.
New methods, modeling or machine learning techniques for generating these analytics, can be defined using SIEM tooling services from query editors (using KQL – Kibana Query Language), UEBA (User Entity Behavioral Analytics) and EBA (Entity Behavior Analysis) models. All configurable through user interfaces and can be managed using prebuilt or custom incident timelines. They can flag anomalies and display details of an incident for the full scope of the event and its context.
As these analytics functions become more standard, some SIEM vendors are pairing the traditional log collection with threat detection and response automation. This is key to producing insights from high volumes of data, where machine learning can automate this analysis to identify hidden threats.
Advanced threat detection
Security threats will continually evolve. A ‘Next Gen’ SIEM should be able to adapt to new advanced threats by implementing network security monitoring, endpoint detection and response sandboxing and behavior analytics in combination with one another to identify and quarantine new potential threats. Security teams need specialized tools to monitor, analyze and detect threats across the cyber kill chain. A cyber kill chain being the steps that trace stages of a cyberattack from the early reconnaissance stages to the exfiltration of data. By configuring machine learning and search context analytics services, you can realize a risk-based monitoring strategy that automatically identifies and prioritizes attacks and threats, that the security team can quickly spot and investigate true dangers to your environment.
These are configurations that can be defined in modern day SIEMs, and will result in real time threat detection monitoring of endpoints from anti-virus logs, insecure ports to cloud services. The set goal of threat detection should be not only to detect threats, but also to determine the scope of those threats by identifying where a specific advance threat may have moved to after being initially detected, how that threat should be contained, and how information should be shared.
Incident Response
Our SIEM tutorial wouldn’t be complete without this feature. Incident response is an organizational process that allows security teams to contain security incidents or cyber attacks and prevent or control damages. Many organizations need to develop proactive incident response capabilities that will actively search corporate systems for signs of a cyber attack. Threat hunting is the core activity of proactive incident response, which is carried out by security analysts. It typically involves querying security data using a SIEM, and running vulnerability scans or penetration tests against organizational systems. The objective is to discover suspicious activity or anomalies that represent a security incident.
An effective incident response strategy needs a robust SIEM platform to identify, track and reassign incidents. This can add the capability of automation and orchestration to your SOC (Security Operation Center) making your cyber security incident response team more productive. A SOC can use customizable tools in the SIEM, designed for security incidents, ensuring that threats do not slip through the cracks.
Other key capabilities should include the ability to either manually or automatically aggregates events, support for APIs that can be used to pull data from or push information to third-party systems, an ability to gather legally admissible forensics evidence, and playbooks that provide organizations with guidance on how to respond to specific types of incidents. SIEM solutions should display the security information in a simple format, such as graphics or dashboards.
SOC Automation
Modern day SIEMs will leverage Security Orchestration and Automation (SOAR) technology that helps identify and automatically respond to security incidents, and supports incident investigation by SOC team members. The foundational technology of a SOC is a SIEM system. The SIEM will use statistical models to find security incidents and raise alerts about them. These alerts will come with crucial contextual information. A SIEM functions as a ‘single pane of glass’ which enables the SOC to monitor enterprise systems.
Monitoring is a key function of tools used in the SOC. The SOC is responsible for enterprise-wide monitoring of IT systems and user accounts, and also monitoring of the security tools themselves. An example is ensuring antivirus is installed and updated on all organizational systems. The main tool that orchestrates monitoring is the SIEM.
SOC automation benefits from SOAR integration with SIEM. A SOAR platform will take things a step further by combining comprehensive data gathering, case management, standardization, workflow and analytics to provide organizations the ability to implement sophisticated defense-in-depth capabilities. A SOAR’s main benefit to a SOC, is that it can automate and orchestrate time-consuming, manual tasks using playbooks, including opening a ticket in a tracking system, such as JIRA, without requiring any human intervention. This would allow engineers and analysts to better use their specialized skills.
All in all…
SIEM tools are proving to be more important than ever in modern times of cyber security. They are becoming undeniably useful in being able to draw together data and threats from across your IT environment into a single easy-to-use dashboard. Many of ‘Next Gen SIEM’ tools are configured to flag suspect patterns on their own and sometimes even resolve the underlying issue automatically. The best SIEM tools are adept at using past trends to differentiate between actual threats and legitimate use, enabling you to avoid false alarms while simultaneously ensuring optimal protection.
This SIEM tutorial was aimed at providing context and clarity to the role of an effective SIEM provider. Any provider that is missing these capabilities should be investigated, to ensure they’re the right fit for you and your security operations.
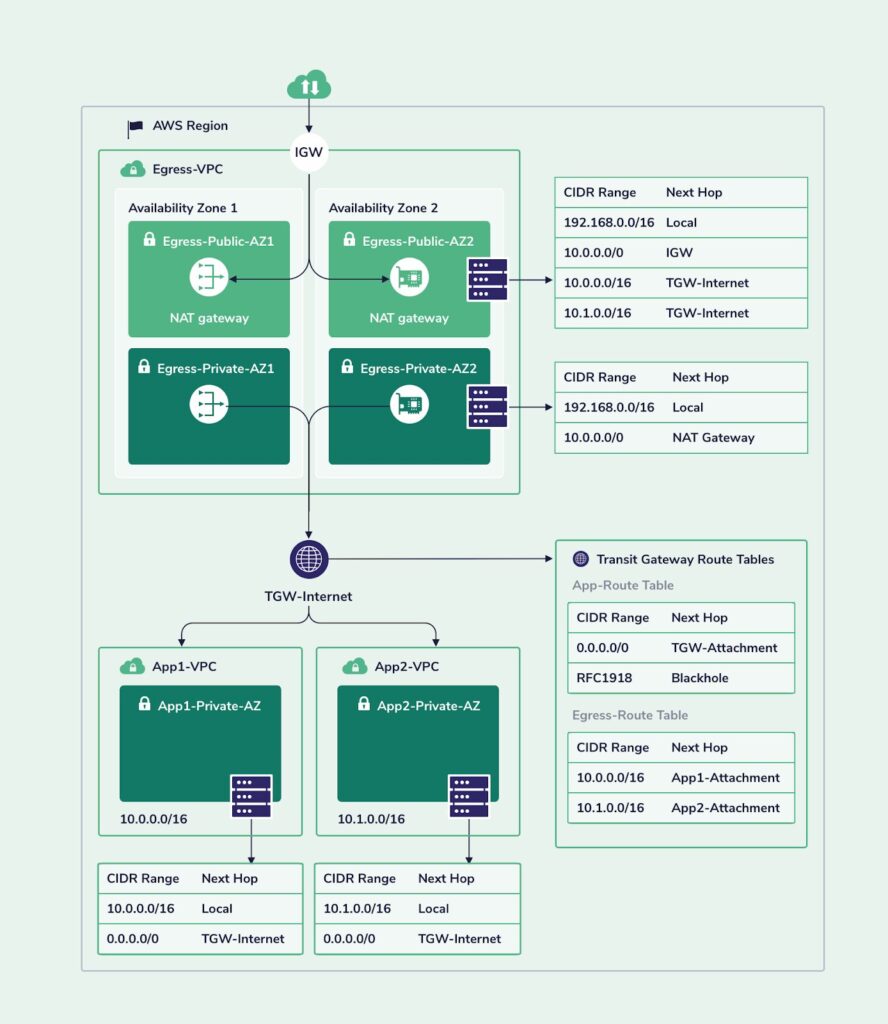
In a previous post, we looked at an example of a fictional bookstore company and recommended mirroring strategies for that specific scenario. In this post, we’ll be looking at a fictional bank and recommended mirroring strategies for their network traffic.
For a list of the most commonly used strategies, check out our traffic mirroring tutorial.
GoldenBank
In this scenario, the client is running two different services, in two different private VPCs. The two VPCs cannot communicate with each other. The reverse proxies handle the majority of the traffic and perform basic request validations such as URIs and web methods and possibly also parameters type validation and then forward the request to the frontend servers.
Unlike the previous scenario, the connection between the reverse proxy and the frontend servers is also encrypted in TLS. The frontend servers perform business context validation of the requests and then process them by sending requests to the backend servers.
Close-up App1
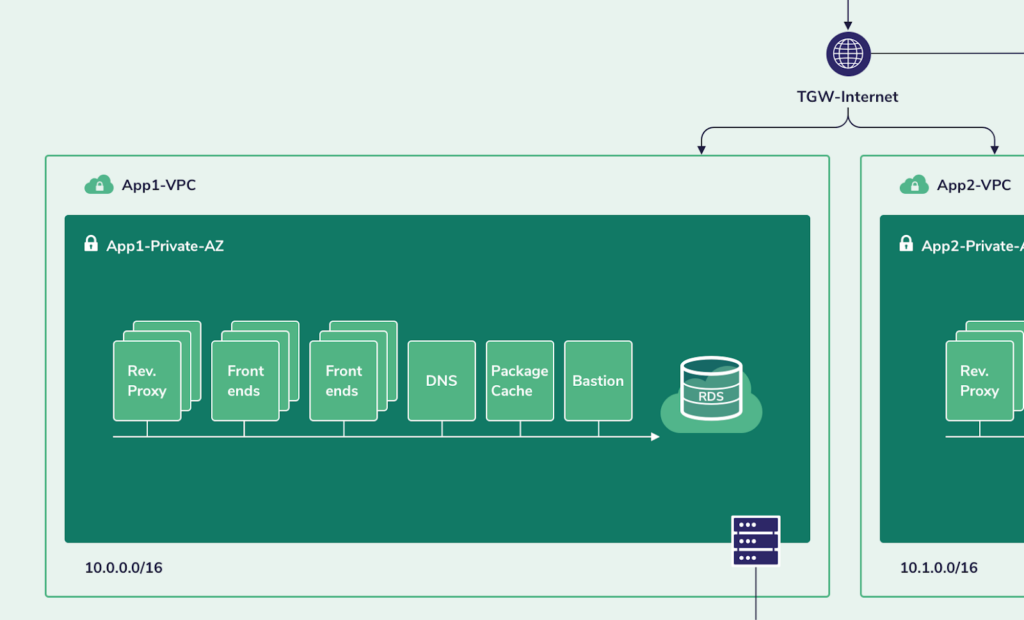
Close-up App2
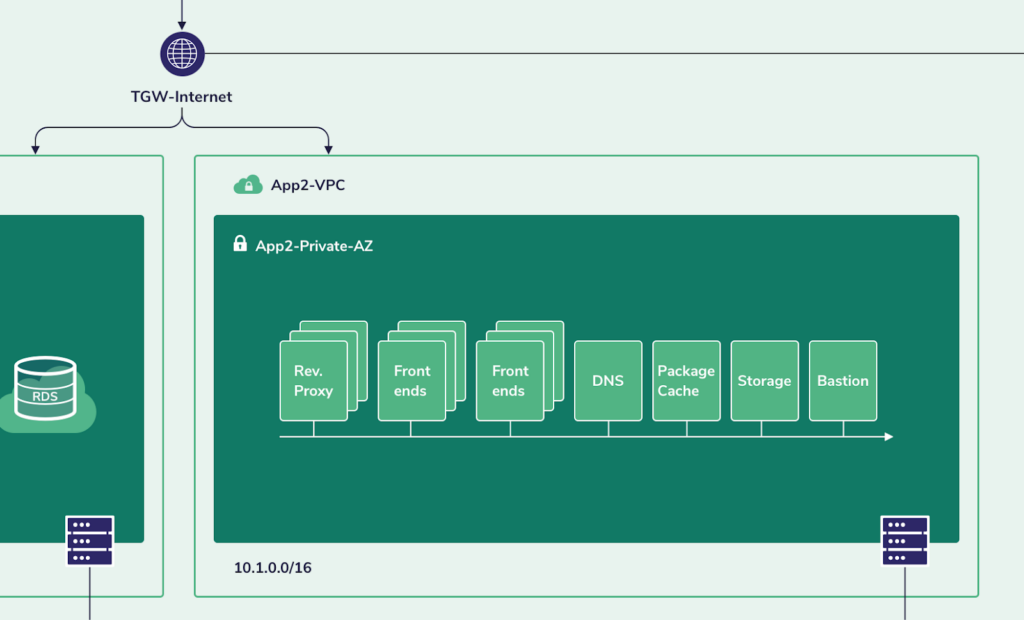
The backend servers in app1 rely on a storage server, while the backend servers of app2 rely on an AWS RDS service.
Following are the details of the security groups of all instances in both applications’ VPCs:
VPC App1
Rev Proxy
(No public IP)
| From | To | Service | Status |
|---|---|---|---|
| any | any | HTTP/tcp | Allow |
| any | any | HTTPS/tcp | Allow |
| 10.0.0.0/16 | Frontend | HTTPS/tcp | Allow |
| 10.0.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.0.0.0/16 | DNS | DNS/udp | Allow |
| 10.0.0.0/16 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
Frontend
(No public IP)
| From | To | Service | Status |
|---|---|---|---|
| Rev. Proxy | 10.0.0.0/16 | HTTPS/tcp | Allow |
| 10.0.0.0/16 | Backend | Custom ports set | Allow |
| 10.0.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.0.0.0/16 | DNS | DNS/udp | Allow |
| 10.0.0.0/16 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
Backend
(No Public IP)
| From | To | Service | Status |
|---|---|---|---|
| Frontend | 10.0.0.0/16 | Custom ports set | Allow |
| 10.0.0.0/16 | Storage | NFS/udp | Allow |
| 10.0.0.0/16 | Storage | NFS/tcp | Allow |
| 10.0.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.0.0.0/16 | DNS | DNS/udp | Allow |
| 10.0.0.0/16 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
Storage
(No Public IP)
| From | To | Service | Status |
|---|---|---|---|
| Backend | 10.0.0.0/16 | NFS/udp | Allow |
| Backend | 10.0.0.0/16 | NFS/tcp | Allow |
| 10.0.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.0.0.0/16 | DNS | DNS/udp | Allow |
| 10.0.0.0/16 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
DNS
(No Public IP)
| From | To | Service | Status |
|---|---|---|---|
| 10.0.0.0/16 | any | DNS/udp | Allow |
| 10.0.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.0.0.0/16 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
Package Cache
(No Public IP)
| 10.0.0.0/16 | any | HTTP/tcp, HTTPS/tcp | Allow |
| 10.0.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.0.0.0/16 | DNS | DNS/udp | Allow |
Here are our visibility recommendations for similar networks:
Reverse proxies and front-end servers
Outbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Monitor everything * | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
* Even though most of the traffic is encrypted since it would include responses to client requests, the outbound traffic is still extremely valuable. It can indicate the size of the data being sent to the client and assist in detecting large data leaks, it can detect connections originating from the reverse proxy itself and help detect command and control connections, it can also detect connections or connection attempts to other servers other than the frontend servers which can detect lateral movement.
Inbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Drop HTTPS* | reject | TCP | – | 443 | 0.0.0.0/0 | 10.0.0.0/16 |
| 200 | Monitor everything else | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
* Since the incoming traffic on HTTPS is encrypted, the only thing it can indicate is its volume over time which can indicate certain types of DoS or DDoS and also the validity of the certificates used. So if the traffic volume is expected to be high, we would recommend excluding this traffic.
Backend servers
Since the frontend servers are contacting these servers with requests that are supposed to be valid after the checks done by the proxy and frontend servers, the traffic volume is expected to be significantly lower than traffic volume to the proxy and frontend servers.
Also, since this is the last chance to detect malicious traffic before it reaches the database, we believe that all traffic from these servers should be mirrored. However, if this is still too expensive for your organization, we would recommend that you use the following mirroring configuration to at least be able to tell if a backend server is behaving abnormally which may indicate that it has already been breached:
Outbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Exclude file service activity ** | reject | TCP | – | NFS | 10.0.0.0/16 | 10.0.0.0/16 |
| 200 | Exclude file service activity ** | reject | UDP | – | NFS | 10.0.0.0/16 | 10.0.0.0/16 |
| 300 | Monitor everything * | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
* – Although this rule will also mirror the server’s responses to frontend requests we do recommend that you mirror it since it might also contain HTTPS connections initiated by malware running on the proxy servers to command and control servers. Also, this might include unintended responses that will indicate that an attack (such as XSS or SQL Injection) took place.
** – Since the filesystem activity is usually heavy, we would recommend you avoid mirroring this type of traffic unless it is highly valuable in your application or network architecture.
Inbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Monitor everything else | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
Storage servers
Outbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Exclude file service activity * | reject | TCP | – | NFS | 10.0.0.0/16 | 10.0.0.0/16 |
| 200 | Exclude file service activity * | reject | UDP | – | NFS | 10.0.0.0/16 | 10.0.0.0/16 |
| 300 | Monitor everything | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
DNS server
Since this server generates a very minimal amount of traffic that is so extremely valuable for detecting so many types of attacks we recommend that you would mirror all traffic in and out of this server.
Package cache server
Since this server is responsible for packages installations on all other servers, the data from and to this server can answer questions like who installed what and when, which can be crucial in a forensic investigation and for detecting installation of malicious tools on the server.
Also, the traffic volume from and to this server is expected to be quite low. Therefore, we recommend that you would mirror all traffic in and out of this server.
Bastion server
Since this server is serving as the only way to manage all other servers, provided that it is being used to update the code on the various servers, install required packages, etc., the traffic volume should be relatively low and the value of the data it can provide is extremely high and therefore we recommend that you would mirror all traffic in and out of this server.
VPC App2
Rev Proxy
(No Public IP)
| any | any | HTTP/tcp | Allow |
| any | any | HTTPS/tcp | Allow |
| 10.1.0.0/16 | Frontend | HTTPS/tcp | Allow |
| 10.1.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.1.0.0/16 | DNS | DNS/udp | Allow |
| 10.1.0.0/16 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
Frontend
(No Public IP)
| Rev. Proxy | 10.1.0.0/16 | HTTPS/tcp | Allow |
| 10.1.0.0/16 | Backend | Custom ports set | Allow |
| 10.1.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.1.0.0/16 | DNS | DNS/udp | Allow |
| 10.1.0.0/16 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
Backend
(No Public IP)
| Frontend | 10.0.0.0/16 | Custom ports set | Allow |
| 10.1.0.0/16 | RDS | DB ports | Allow |
| 10.1.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.1.0.0/16 | DNS | DNS/udp | Allow |
| 10.1.0.0/16 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
RDS
(No Public IP)
| Backend | 10.1.0.0/16 | DB ports | Allow |
| 10.1.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.1.0.0/16 | DNS | DNS/udp | Allow |
| 10.1.0.0/16 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
DNS
(No Public IP)
| 10.1.0.0/16 | any | DNS/udp | Allow |
| 10.1.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.1.0.0/16 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
Package Cache
(No Public IP)
| 10.1.0.0/16 | any | HTTP/tcp, HTTPS/tcp | Allow |
| 10.1.0.0/16 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 10.1.0.0/16 | DNS | DNS/udp | Allow |
This network architecture is quite complex and would require an approach that would combine multiple data sources to provide proper security for it. In addition, it involves traffic that is completely encrypted, storage servers that are contacted via encrypted connections, and also AWS services that cannot be mirrored to the STA.
Here are our visibility recommendations for similar networks:
Reverse Proxies and Front-end servers
Outbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Monitor everything * | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
* Even though most of the traffic is encrypted since it would include responses to clients requests, the outbound traffic is still extremely valuable. It can indicate the size of the data being sent to the client and assist in detecting large data leaks, it can detect connections originating from the reverse proxy itself and help detect command and control connections, it can also detect connections or connection attempts to other servers other than the frontend servers which can detect lateral movement.
Inbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Drop HTTPS* | reject | TCP | – | 443 | 0.0.0.0/0 | 10.1.0.0/16 |
| 200 | Monitor everything else | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
* Since the incoming traffic on HTTPS is encrypted, the only thing it can indicate is its volume over time which can indicate certain types of DoS or DDoS and also the validity of the certificates used. So if the traffic volume is expected to be high, we would recommend excluding this traffic.
Backend servers
Outbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Monitor everything * | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
* – Since this server is expected to communicate with the RDS service, we would recommend mirroring all the traffic from this instance as this will allow the detection of database-related attacks. In addition, the RDS security group should be configured to allow connections only from the backend server (this can be more strict by configuring the RDS itself to allow connections only if they were identified by a certificate that exists only on the backend server) and an alert should be defined in Coralogix based on CloudTrail logs that would fire if the security group is modified.
Also, by forwarding the database logs from the RDS instance, an alert should be defined in Coralogix so it would be triggered if the database detects connections from other IPs.
Inbound
Since the traffic volume here should be quite low due to the validations done by the proxies and front-end servers, and due to the fact that this is the last point we can tap into the data before it is saved into the DB we recommend that you mirror all incoming traffic from this server
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Monitor everything * | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
DNS server
Since this server generates a very minimal amount of traffic that is so extremely valuable for detecting so many types of attacks we recommend that you mirror all traffic in and out of this server.
Package cache server
Since this server is responsible for packages installations on all other servers, the data from and to this server can answer questions like who installed what when, which can be crucial in a forensic investigation and for detecting installation of malicious tools on the server. Also, the traffic volume from and to this server is expected to be quite low. Therefore, we recommend that you mirror all traffic in and out of this server.
Bastion server
Since this server is serving as the only way to manage all other servers, provided that it is being used to update the code on the various servers, install required packages, etc., the traffic volume should be relatively low and the value of the data it can provide is extremely high and therefore we recommend that you mirror all traffic in and out of this server.
Summary
Just like in any other field of security, there is no real right or wrong here, it’s more a matter of whether or not it is worth the trade-off in particular cases. There are several strategies that can be taken to minimize the overall cost of the AWS traffic monitoring solution and still get acceptable results.
For a list of the most commonly used strategies, check out our traffic mirroring tutorial.
Optimized Security Traffic Mirroring Examples – Part 1
You have to capture everything to investigate security issues thoroughly, right? More often than not, data that at one time was labeled irrelevant and thrown away is found to be the missing piece of the puzzle when investigating a malicious attacker or the source of an information leak.
So, you need to capture every network packet. As ideal as this might be, capturing every packet from every workstation and every server in every branch office is usually impractical and too expensive, especially for larger organizations.
In this post, we’ll look at an example of a fictional bookstore company and the recommended mirroring strategies for that specific scenario.
For a list of the most commonly used strategies, check out our traffic mirroring tutorial.
MyBookStore Company
This example represents a simple book store. The frontend servers hold the code for handling customers’ requests for searching and purchasing books, all the system’s data is stored in the database servers. Currently, the throughput to the website is not extremely high but is expected to grow significantly in the upcoming months due to the new year’s sales.
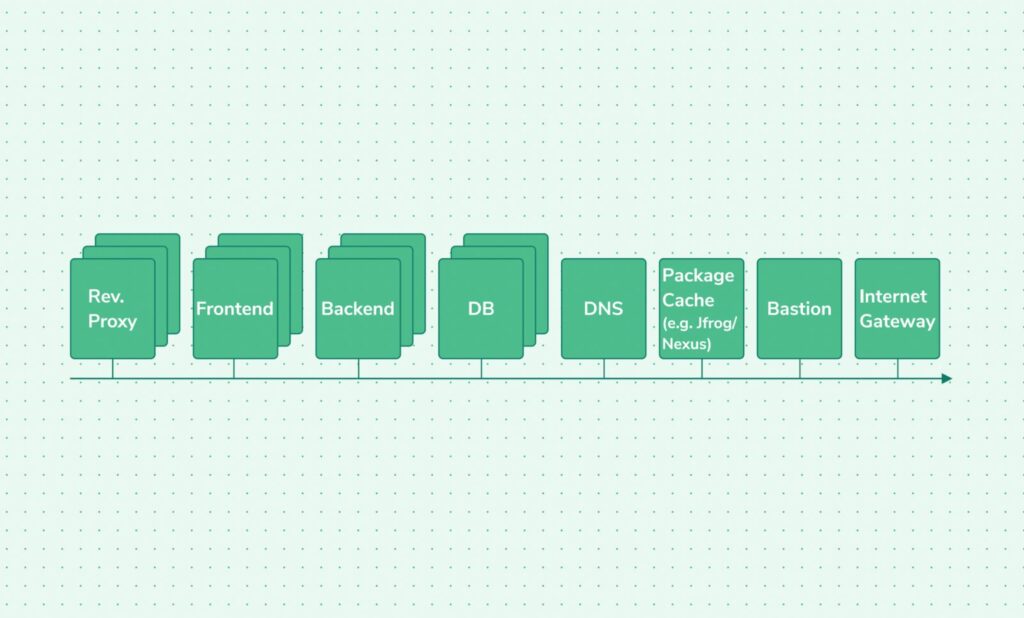
The network diagram above describes a typical network of a SaaS service. It’s a collection of reverse proxies that handle HTTPS encryption and client connections after basic validation, such as URIs paths and sometimes even parameters and HTTP methods. They then send the HTTP requests as HTTP to the frontend servers, making requests to their backend servers that process the data and update or query the DB servers and return the requested result.
Security groups and public IP configuration
The following table represents the network security measures indicated by the allowed connections in and out of each server shown on the diagram.
Rev Proxy
(With public IP)
| From | To | Service | Status |
|---|---|---|---|
| any | any | HTTP/tcp | Allow |
| any | any | HTTPS/tcp | Allow |
| 192.168.1.0/24 | Frontend | HTTP/tcp | Allow |
| 192.168.1.0/24 | any | NTP/udp | Allow |
| Bastion | any | SSH/tcp | Allow |
| 192.168.1.0/24 | DNS | DNS/udp | Allow |
| 192.168.1.0/24 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
Frontend
(No public IP)
| From | To | Service | Status |
|---|---|---|---|
| Rev. Proxy | 192.168.1.0/24 | HTTP/tcp | Allow |
| 192.168.1.0/24 | Backend | Set of custom ports | Allow |
| 192.168.1.0/24 | any | NTP/udp | Allow |
| Bastion | 192.168.1.0/24 | SSH/tcp | Allow |
| 192.168.1.0/24 | DNS | DNS/udp | Allow |
| 192.168.1.0/24 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
Backend
(No public IP)
| From | To | Service | Status |
|---|---|---|---|
| Frontend | 192.168.1.0/24 | Set of custom ports | Allow |
| 192.168.1.0/24 | DB | DB Ports | Allow |
| 192.168.1.0/24 | any | NTP/udp | Allow |
| Bastion | 192.168.1.0/24 | SSH/tcp | Allow |
| 192.168.1.0/24 | DNS | DNS/udp | Allow |
| 192.168.1.0/24 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
DB
(No public IP)
| From | To | Service | Status |
|---|---|---|---|
| Backend | 192.168.1.0/24 | DB ports/tcp | Allow |
| 192.168.1.0/24 | any | NTP/udp | Allow |
| Bastion | 192.168.1.0/24 | SSH/tcp | Allow |
| 192.168.1.0/24 | DNS | DNS/udp | Allow |
| 192.168.1.0/24 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
DNS
(No public IP)
| From | To | Service | Status |
|---|---|---|---|
| 192.168.1.0/24 | DNS | DNS/udp | Allow |
| 192.168.1.0/24 | any | NTP/udp | Allow |
| 192.168.1.0/24 | any | DNS/udp | Allow |
| Bastion | 192.168.1.0/24 | SSH/tcp | Allow |
| 192.168.1.0/24 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
Packages Cache
(No public IP)
| From | To | Service | Status |
|---|---|---|---|
| 192.168.1.0/24 | any | HTTP/tcp, HTTPS/tcp | Allow |
| 192.168.1.0/24 | any | NTP/udp | Allow |
| 192.168.1.0/24 | any | DNS/udp | Allow |
| Bastion | 192.168.1.0/24 | SSH/tcp | Allow |
Bastion
(With public IP)
| From | To | Service | Status |
|---|---|---|---|
| Well defined set of IP addresses | 192.168.1.0/24 | SSH/tcp | Allow |
| 192.168.1.0/24 | any | NTP/udp | Allow |
| 192.168.1.0/24 | DNS | DNS/udp | Allow |
| 192.168.1.0/24 | Packages Cache | HTTP/tcp, HTTPS/tcp | Allow |
In this setup, the only servers that are exposed to the Internet and expected to be reachable by other servers on the Internet are the proxy servers and the bastion server. All other servers do not have a public IP address assigned to them.
All DNS queries are expected to be sent to the local DNS server, resolving them against other DNS servers on the Internet.
Package installations and updates for all the servers on this network are expected to be handled against the local packages caching server. So all other servers will not need to access the Internet at all except for time synchronization against public NTP servers.
SSH connections to the servers are expected to happen only via the bastion server and not directly from the Internet.
In this scenario, we would recommend using the following mirroring configuration by server type.
Reverse Proxies
Since these servers are contacted by users from the Internet over a TLS encrypted connection, most of the traffic to it should be on port 443 (HTTPS) and its value to traffic rate ratio is expected to be quite low, we would recommend the following mirror filter configuration:
Outbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Monitor everything * | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
* Note – Although this rule will also mirror the server’s encrypted responses to the HTTPS requests we do recommend that you mirror it since it might also contain HTTPS connections initiated by malware running on the proxy servers to command and control servers and especially since the traffic volume of the server’s responses is not expected to be extremely high.
Inbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Exclude incoming HTTPS | reject | TCP | – | 443 | 0.0.0.0 | <your servers subnet> |
| 200 | Monitor everything else | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
Frontend servers
Since the frontend servers receive the unencrypted traffic they are essentially the first place on the network in which we can detect attacks against the system and therefore their traffic data is very valuable from an information security perspective.
This is why we believe that you would mirror any traffic from and to these servers. This will, of course, include the valid traffic by the customers. Although this can be extremely valuable for creating a good baseline that can later be used to detect anomalies, it can also be rather expensive for the organization.
For such cases we would recommend the following mirroring configuration for detecting abnormal behavior of the frontend servers that can indicate a cyberattack that is currently in progress:
Outbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Monitor everything * | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
* Note – Although this rule will also mirror the server’s responses to the HTTPS requests, we do recommend that you mirror it since it might also contain HTTPS connections initiated by malware running on the proxy servers to command and control servers. Also, this might include unintended responses that will indicate that an attack (such as XSS or SQL Injection) took place.
Inbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Exclude incoming HTTPS | reject | TCP | – | 80 | 0.0.0.0/0 | <your servers subnet> |
| 200 | Monitor everything else | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
Backend servers
Since the frontend servers are contacting these servers with requests that are supposed to be valid after the checks done by the proxy and frontend servers, the traffic volume is expected to be significantly lower than traffic volume to the proxy and frontend servers.
Also, since this is the last chance to detect malicious traffic before it reaches the database, we believe that all traffic from these servers should be mirrored. However, if this is still too expensive for your organization, we would recommend that you use the following mirroring configuration to at least be able to tell if a backend server is behaving abnormally, which may indicate that it has already been breached:
Outbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Monitor everything * | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
* Note – Although this rule will also mirror the server’s responses to frontend requests we do recommend that you mirror it since it might also contain HTTPS connections initiated by malware running on the proxy servers to command and control servers. Also, this might include unintended responses that will indicate that an attack (such as XSS or SQL Injection) took place.
Inbound
| Rule number | Description | Rule action | Protocol | Source port range | Destination port range | Source CIDR block | Destination CIDR block |
| 100 | Exclude incoming HTTPS | reject | TCP | – | Set of custom ports | <your servers subnet> | <your servers subnet> |
| 200 | Monitor everything else | accept | All protocols | – | – | 0.0.0.0/0 | 0.0.0.0/0 |
Databases
Since this server is at the heart of the customer’s system, we recommend that you would mirror all traffic in and out of this server.
DNS server
Since this server generates a very minimal amount of traffic that is so extremely valuable for detecting so many types of attacks we recommend that you would mirror all traffic in and out of this server.
Package cache server
Since this server is responsible for packages installations on all other servers, the data from and to this server can answer questions like who installed what and when which can be crucial in a forensic investigation and for detecting installation of malicious tools on the server. Also, the traffic volume from and to this server is expected to be quite low. Therefore, we recommend that you would mirror all traffic in and out of this server.
Bastion server
Since this server is serving as the only way to manage all other servers, provided that it is being used to update the code on the various servers, install required packages, etc., the traffic volume should be relatively low and the value of the data it can provide is extremely high and therefore we recommend that you would mirror all traffic in and out of this server.
Summary
Just like in any other field of security, there is no real right or wrong here, it’s more a matter of whether or not it is worth the trade-off in particular cases. There are several strategies that can be taken to minimize the overall cost of the AWS traffic monitoring solution and still get acceptable results.
For a list of the most commonly used strategies, check out our traffic mirroring tutorial.
Have You Forgotten About Application-Level Security?Security is one of the most changeable landscapes in technology at the moment. With innovations, come new threats, and it seems like every week brings news of a major organization succumbing to a cyber attack. We’re seeing innovations like AI-driven threat detection and zero-trust networking continuing to be a huge area of investment. However, security should never be treated as a single plane.
Here at Coralogix, we’re firm believers that observability is the backbone of good security practice. That’s why, in this piece, we’re going to examine what’s in the arsenal when it comes to protecting your platforms at their core: the application level.
The cybersecurity picture today
Trends in cyber security seem to revolve around two key facets: detection and recovery. Detection, because stopping an attack before it happens is less costly than recovery. Recovery, because there is a certain inevitability associated with cyber-attacks and organizations want to be best prepared for such an eventuality. GDPR logging and monitoring and NIS require disclosure from an organization hit by a cyberattack within 72 hours, so it’s easy to see companies are today focussing on these pillars.
In terms of attack style, three main types dominate a CISO’s headspace in 2021. These are (in no particular order), supply-chain attacks, insider threats, and ransomware.
Code-layer security for your application
It’s fair to say that applications need safe and secure code to run without the threat of compromising other interdependent systems. The SolarWinds cyber attack is a great example of when compromised code had a devastating knock-on effect. Below, we’ll explore how you can boost your security at a code level.
Maintain a repository
Many companies will employ a trusted code repository to ensure that they aren’t shipping any vulnerabilities. You can supercharge the use of a repository by implementing GitOps as a methodology. Not only does this give you ship and roll-back code quickly, but with the Coralogix Kubernetes Operator, you can keep track of these deployments with your observability platform.
Write secure code
This seems like an obvious suggestion, but it shouldn’t be overlooked. Vulnerabilities in Java code occupy the top spots in the OWASP top 10, so ensure your engineers are well versed in shortcomings around SSL/TLS libraries. While there are tools available which scan your code for the best-known vulnerabilities, they’re no substitute for on-the-ground knowledge.
Monitor your code
Lack of proper monitoring, alerting, and logging is cited as a key catalyst of application-level security problems. Fortunately, Coralogix has a wide range of integrations for the most popular programming languages so that you can monitor key security events at a code level.
Cloud service security for your application
Public cloud provides a range of benefits that organizations look to capitalize on. However, the public cloud arena brings its own additional set of application security considerations.
Serverless monitoring
In a 2019 survey, 40% of respondents indicated that they had adopted a serverless architecture. Function as a Service (FaaS) applications have certainly brought huge benefits for organizations, but also bring a new set of challenges. On AWS, the FaaS offerings are Lambda and S3 (which is stateful backend storage for Lambda). The Internet is littered with examples of security incidents directly related to S3 security problems, most famously Capital One’s insider threat fiasco. This is where tools like Coralogix’s Cloudwatch integration can be useful, allowing you to monitor changes in roles and permissions in your Coralogix dashboard. Coralogix also offers direct integration with AWS via its Serverless Application Repository, for all your serverless security monitoring needs.
Edge computing
Edge computing is one of the newer benefits realized by cloud computing. It greatly reduces the amount of data in flight, which is good for security. However, it also relies on a network of endpoint devices for processing. There are numerous considerations for security logging and monitoring when it comes to IoT or edge computing. A big problem with monitoring these environments is the sheer amount of data generated and how to manage it. Using an AI-powered tool, like Loggregation, to help you keep on top of logging outputs is a great way of streamlining your security monitoring.
Container security for your application
If you have a containerized environment, then you’re probably aware of the complexity of managing its security. While there are numerous general containerized environment security considerations, we’re going to examine the one most relevant to application-level security.
Runtime Security
Runtime security for containers refers to the security approach for when the container is deployed. Successful container runtime security is heavily reliant on an effective container monitoring and observability strategy.
Runtime security is also about examining internal network traffic, instead of just relying on traditional firewalling. You also have to monitor the orchestration platforms (for example Kubernetes or Istio) to make sure you don’t have vulnerabilities there. Coralogix provides lots of different Kubernetes integrations, including Helm charts, to give you that vital level of granular observability.
What’s the big deal?
With many organizations being increasingly troubled by cyberattacks, it’s important to make sure that security focus isn’t just on the outer layer, for example, firewalls. In this article, we’ve highlighted steps you can take to effectively monitor your applications and their components to increase your system security, from the inside out.
What’s the biggest takeaway from this, then? Well, you can monitor your code security, cloud services, and container runtime. But don’t ever do it in isolation. Coralogix gives you the ability to overlay and contextualize this data with other helpful metrics, like firewalls, to keep your vital applications secure and healthy.
5 Cybersecurity Tools to Safeguard Your BusinessWith the exponential rise in cybercrimes in the last decade, cybersecurity for businesses is no longer an option — it’s a necessity. Fuelled by the forced shift to remote working due to the pandemic, US businesses saw an alarming 50% rise in reported cyber attacks per week from 2020 to 2021. Many companies still use outdated technologies, unclear policies, and understaffed cybersecurity teams to target digital attacks.
So, if you’re a business looking to upgrade its cybersecurity measures, here are five powerful tools that can protect your business from breaches.
1. Access protection
Designed to monitor outgoing and incoming network traffic, firewalls are the first layer of defense from unauthorized access in private networks. They are easy to implement, adopt, and configure based on security parameters set by the organization.
Among the different types of firewalls, one of the popular choices among businesses is a next-generation firewall. A next-generation firewall can help protect your network from threats through integrated intrusion prevention, cloud security, and application control. A proxy firewall can work well for companies looking for a budget option.
Even though firewalls block a significant portion of malicious traffic, expecting a firewall to suffice as a security solution would be a mistake. Advanced attackers can build attacks that can bypass even the most complex firewalls, and your organization’s defenses should catch up to these sophisticated attacks. Thus, instead of relying on the functionality of a single firewall, your business needs to adopt a multi-layer defense system. And one of the first vulnerabilities you should address is having unsecured endpoints.
2. Endpoint protection
Endpoint Protection essentially refers to securing devices that connect to a company’s private network beyond the corporate firewall. Typically, these range from laptops, mobile phones, and USB drives to printers and servers. Without a proper endpoint protection program, the organization stands to lose control over sensitive data if it’s copied to an external device from an unsecured endpoint.
Softwares like antivirus and anti-malware are the essential elements of an endpoint protection program, but the current cybersecurity threats demand much more. Thus, next-generation antiviruses with integrated AI/ML threat detection, threat hunting, and VPNs are essential to your business.
If your organization has shifted to being primarily remote, implementing a protocol like Zero Trust Network Access (ZTNA) can strengthen your cybersecurity measures. Secure firewalls and VPNs, though necessary, can create an attack surface for hackers to exploit since the user is immediately granted complete application access. In contrast, ZTNA isolates application access from network access, giving partial access incrementally and on a need-to-know basis.
Combining ZTNA with a strong antivirus creates multi-layer access protection that drastically reduces your cyber risk exposure. However, as we discussed earlier, bad network actors who can bypass this security will always be present. Thus, it’s essential to have a robust monitoring system across your applications, which brings us to the next point…
3. Log management & Observability
Log management is a fundamental security control for your applications. Drawing information from event logs can be instrumental to identifying network risks early, mitigating bad actors, and quickly mitigating vulnerabilities during breaches or event reconstruction.
However, many organizations still struggle with deriving valuable insights from log data due to complex, distributed systems, inconsistency in log data, and format differences. In such cases, a log management system like Coralogix can help. It creates a centralized, secure dashboard to make sense of raw log data, clustering millions of similar logs to help you investigate faster. Our AI-driven analysis software can help establish security baselines and alerting systems to identify critical issues and anomalies.
A strong log monitoring and observability system also protects you from DDoS attacks. A DDoS attack floods the bandwidth and resources of a particular server or application through unauthorized traffic, typically causing a major outage.
With observability platforms, you can get ahead of this. Coralogix’s native Cloudflare integrations combined with load balancers give you the ability to cross-analyze attack and application metrics and enable your team to mitigate such attacks. Thus, you can effectively build a DDOS warning system to detect attacks early.
Along with logs, another critical business data that you should monitor regularly are emails. With over 36% of data breaches in 2022 attributed to phishing scams, businesses cannot be too careful.
4. Email gateway security
As most companies primarily share sensitive data through email, hacking email gateways is a prime target for cybercriminals. Thus, a top priority should be robust filtering systems to identify spam and phishing emails, embedded code, and fraudulent websites.
Email gateways act as a firewall for all email communications at the network level — scanning and auto-archiving malicious email content. They also protect against business data loss by monitoring outgoing emails, allowing admins to manage email policies through a central dashboard. Additionally, they help businesses meet compliance by safely securing data and storing copies for legal purposes.
However, the issue here is that sophisticated attacks can still bypass these security measures, especially if social engineering is involved. One wrong click by an employee can give hackers access to an otherwise robust system. That’s why the most critical security tool of them all is a strong cybersecurity training program.
5. Cybersecurity training
Even though you might think that cybersecurity training is not a ‘tool,’ a company’s security measures are only as strong as the awareness among employees who use them. In 2021, over 85% of data breaches were associated with some level of human error. IBM’s study even found out that the breach would not have occurred if the human element was not present in 19 out of 20 cases that they analyzed.
Cybersecurity starts with the people, not just the tools. Thus, you need to implement a strong security culture about security threats like phishing and social engineering in your organization. All resources related to cybersecurity should be simplified and made mandatory during onboarding. These policies should be further reviewed, updated, and re-taught semi-annually in line with new threats.
Apart from training, the execution of these policies can mean the difference between a hackable and a secure network. To ensure this, regular workshops and phishing tests should also be conducted to identify potential employee targets. Another way to increase the effectiveness of these training is to send out cybersecurity newsletters every week.
Some companies like Dell have even adopted a gamified cybersecurity training program to encourage high engagement from employees. The addition of screen locks, multi-factor authentication, and encryption would also help add another layer of security.
Upgrade your cybersecurity measures today!
Implementing these five cybersecurity tools lays a critical foundation for the security of your business. However, the key here is to understand that, with cyberattacks, it sometimes just takes one point of failure. Therefore, preparing for a breach is just as important as preventing it. Having comprehensive data backups at regular intervals and encryption for susceptible data is crucial. This will ensure your organization is as secure as your customers need it to be — with or without a breach!
Trying to work out the best security tool is a little like trying to choose a golf club three shots ahead – you don’t know what will help you get to the green until you’re in the rough.
Traditionally, when people think about security tools, firewalls, IAM and permissions, encryption, and certificates come to mind. These tools all have one thing in common – they’re static. In this piece, we’re going to examine the security tools landscape and understand which tool you should be investing in.
Security Tools – The Lay of the Land
The options available today to the discerning security-focused organization are diverse. From start-ups to established enterprises, understanding who makes the best firewalls or who has the best OWASP top ten scanning is a nightmare. We’re not here to compare vendors, but more to evaluate the major tools’ importance in your repertoire.
Firewalls and Intrusion Detection Systems
Firewalls are a must-have for any organization, no one is arguing there. Large or small, containerized or monolithic, without a firewall you’re in big trouble.
Once you’ve selected and configured your firewall, ensuring it gives the protection you need, you might think you’ve uncovered a silver bullet. The reality is that you have to stay on top of some key parameters to make sure you’re maximizing the protection of the firewall or IDS. Monitoring outputs such as traffic, bandwidth, and sessions are all critical to understanding the health and effectiveness of your firewalls.
Permissions Tooling
The concept of Identity and Access Management has evolved significantly in the last decade or so, particularly with the rise of the cloud. The correct provisioning of roles, users, and groups for the purposes of access management is paramount for keeping your environment secure.
Staying on top of the provisioning of these accesses is where things can get a bit difficult. The ability to understand (through a service such as AWS Cloudwatch) all of the permissions assigned to individuals, applications, and functions alike is difficult to keep track of. While public CSPs have made this simpler to keep track of, the ability to view permissions in the context of what’s going on in your system gives enhanced security and confidence.
Encryption Tooling
Now more than ever, encryption is at the forefront of any security-conscious individual’s mind. Imperative for protecting both data at rest and in flight, encryption is a key security tool.
Once implemented, you need to keep track of your encryption, ensuring that it remains in place for whatever you’re trying to protect. Be it disk encryption or encrypted traffic on your network, it needs to be subject to thorough monitoring.
Monitoring is the Foundation
With all of the tool types that we’ve covered, there is a clear and consistent theme. Not only do all of the above tools have to be provisioned, they also rely on strong and dependable monitoring to assist proactive security and automation.
Security Incident Event Management
The ability to have a holistic view of all of your applications and systems is key. Not only is it imperative to see the health of your network, but if part of your application stack is underperforming it can be either symptomatic of, or inviting to, malicious activity.
SIEM dashboards are a vital security tool which use the concept of data fusion to provide advanced modelling and provide context to otherwise isolated metrics. Using advanced monitoring and altering, the best SIEM products will not only dashboard your system health and events in realtime, but also retain log data for a period of time to provide event timeline reconstruction.
The Power of Observability
Observability is the new thing in monitoring. It expands beyond merely providing awareness of system health and security status to giving cross-organizational insights which drive real business outcomes.
What does this mean for our security tooling? Well, observability practises drive relevant insights to the individuals most empowered to act on them. In the instance of system downtime, this would be your SREs. In the case of an application vulnerability, this would be your DevSecOps ninjas.
An observability solution working in real time will not only provide telemetry on the health and effectiveness of your security tool arsenal, but will also give real-time threat detection.
Coralogix Cloud Security
Even if you aren’t certain which firewall or encryption type comes out on top, you can be certain of Coralogix’s cloud security solution.
With a quick, 3-step setup and out-of-the-box functionality including real-time monitoring, you can be sure that your tools and engineers can react in a timely manner to any emerging threats.
Easily connect any data source to complete your security observability, including Audit logs, Cloudtrail, GuardDuty or any other source. Monitor your security data in one of 100+ pre-built dashboards or easily build your own using our variety of visualization tools and APIs.
What is Red Teaming in Cyber Security? The Complete Guide
Red teaming explained
Red teaming is the practice of asking a trusted group of individuals to launch an attack on your software or your organization so that you can test how your defenses will hold up in a real-world situation. Any organization reliant on software – including banks, healthcare providers, government institutions, or logistics companies – is potentially vulnerable to cyberattacks, such as ransomware or data exfiltration.
For software providers, red teaming is an effective way to test the security of your product or service and protect your users from attacks made via your software in the future. A red team can either be an internal team or a third-party group of ethical hackers hired explicitly for the task.
Red teaming vs. blue teaming
The term “Red Team” originates from the military practice of using war games to challenge operational plans by testing how defenses perform against an intelligent adversary. The “Red Team” refers to the group playing the enemy role, whose job is to get past the defenses of the “Blue Team,” who represent the home nation.
In a cybersecurity context, the red team is a group of ethical hackers tasked with launching an attack. At the same time, the Blue Team refers to the security analysts, operations team, or software developers responsible for the system(s) under attack. Typically, the red team is tasked with a particular goal, such as accessing sensitive data, disrupting a service, or planting malware that will enable future attacks.
The red team’s only information about the system is what could be gleaned by an actual attacker. The Blue Team is not informed in advance of the attack and should treat any suspicious activity as a live situation and address it accordingly. The red team responds to any defensive measure by adapting their approach and persevering until they reach their goal or are routed by the Blue Team.
Once the attack is concluded, the red team reports their activities, including any vulnerabilities they found and any defenses that worked against them. This information is then used by the security team and/or software developers to strengthen their defenses for the future. The sharing of information from the red team following the exercise is an essential part of the process, turning the simulated attack into an opportunity to improve security operations.
In some contexts, you may come across the term “purple team,” referring to an amalgamation of red and blue teams. The aim of creating a purple team is to focus on sharing the tactics, techniques, and procedures used so that the security staff can learn from them. However, to run an effective simulation, it’s essential that the red team does not have insider knowledge that an attacker would lack, and the blue team reacts as they would in a real-world scenario. Equally, to get value from red team exercises, it’s essential that the red team shares their findings to improve security.
Red teaming vs. Pen testing
Although closely related, red teaming is not the same as penetration testing (aka pen testing). While both types of security testing are designed to assess whether an attacker could achieve a particular goal, their scope is different.
With a pen test, your security team would typically be made aware of the test before it takes place. The pen testers will work through multiple tactics to achieve the goal, recording any observations along the way.
Red teaming takes security testing a step further. Because the role of the red team is to emulate real attackers, the security team should be unaware of the details or timing of the attack. Furthermore, the red team will operate by stealth, seeking to evade detection and cover their tracks the same way an actual cybercriminal would work.
To make the simulated attack as accurate as possible, red teams go further than pure software testing and may use social engineering techniques and attempt to breach physical security to pursue their goal, just as an actual attacker would.
What does a Red Team attack?
A red team’s attack will depend on what you’re trying to test – your organization, your software, or a combination of the two (as in the case of software-as-a-service providers). To emulate a real cyberattack, a red team may challenge:
- Your network – by attempting to gain access via open ports, compromised devices, or insecure user accounts, to name just a few options. This applies as much to cloud-hosted systems as it does to on-premise installations. Once inside your network, the red team will try to move laterally to systems of interest, exploiting security vulnerabilities to elevate their privileges.
- Your software – by searching your software for vulnerabilities that will enable many types of attack, from buffer overflow to SQL injection, cross-site scripting, to confused deputy. Red teams might also try fuzzing – a technique that involves finding ways to crash your software and then diagnosing the cause of the crash to find a way to use your program for malicious purposes, such as executing malicious code or accessing data that is used by attackers to create new exploits in software that can then be sold on the dark web, resulting in many future attacks on your users.
- Your physical security – by using tools such as RFID cloners to forge security passes or underhand tactics such as bypassing security camera blind spots or picking locks to access a physical network port or server room.
- Your people – by using social engineering to gain access to your physical premises, plant malware via carefully targeted phishing scams, or retrieve information about your organization that can facilitate an attack.
In practice, these areas overlap, and a red team will often use tactics that cover some or all of these areas. For example, although your remote access protocols might defend your systems from network intrusion, weak building security combined with some simple social engineering could allow your red team (or a malicious actor) to gain entry to your offices and get their hands on an unattended employee laptop or connect their own device to an available network socket.
Once inside your network, they can use privilege escalation tactics to access critical systems. Having gained access, they will demonstrate how they could exfiltrate valuable data or plant malware that could be used to encrypt your files and demand a ransom.
When should you use a Red Team?
While red teaming and pen testing are effective ways of testing your organization’s cyber defenses, they are not designed to provide you with an exhaustive list of all your security vulnerabilities. That’s the role of a vulnerability assessment.
Before you embark on red team testing, it’s vital to lay the groundwork with a detailed vulnerability assessment to identify, prioritize and address as many security flaws as possible. Findings might range from unpatched servers and default admin passwords to use of compromised third-party libraries or failure to sanitize user inputs.
Having addressed all known issues, it’s time to use a threat assessment to identify the highest risks to focus your testing accordingly. The type of cyber-attack you’re most likely to face will depend on your organization and industry.
The lowest level of attacks are those launched by individual opportunistic hackers using known exploits and off-the-shelf tools to see what they can find, from user account credentials to servers on which to deploy cryptocurrency miners.
More high-profile organizations and those with valuable assets are at higher risk from advanced attackers that will invest time in employing underhand tactics to deploy ransomware, steal sensitive information, or craft new exploits for your product or service. Finally, there are nation-state-sponsored attackers with vast resources at their disposal to select strategic targets.
Once you have put your security measures in place and have determined the types of risk you likely face, you can test your defenses with a pen test to check for more complex vulnerabilities. Having fixed all you can, it’s time to see how they stand up against a sustained assault via red teaming.
Ideally, red teaming should be an ongoing activity that continuously assesses your security posture. As changes are made to your systems or software, and new exploits are discovered, you must keep testing your defenses against realistic attack techniques.
What are the benefits of red teaming?
An effective red team will adapt their tactics in response to your defenses, looking for any opportunity to gain access to your systems, which means they are well placed to find unanticipated ways.
Organizations that regularly use red teaming to challenge their security posture can use the findings from those exercises to strengthen their defenses, improve their ability to detect attacks early on, and limit any damage. By emulating all aspects of a likely attack, red teaming tests the ecosystem as a whole rather than just one element of it.
Sharing the results of a red team attack with your employees – mainly where social engineering formed part of the approach – can help minimize complacency and foster a security culture. Showing the impact of a seemingly insignificant breach is often far more compelling than a corporate training video.
Continuous red teaming also provides real-world metrics for your SOC team to measure their performance over time and provide valuable evidence to inform and justify investment in security enhancements.
How does the red team security testing process work?
The starting point for red team activities is to set out their terms of engagement. This should include details of anything that is expressly off-limits, describe how authority is given for an activity, agree on how personal and sensitive information will be handled, and detail the conditions for ceasing a red team attack.
Although your security team (the blue team) should be largely unaware of a red team engagement (including the planned date and time), it’s vital that someone in authority is aware of upcoming activities and can provide the necessary assurances – to both law enforcement and stakeholders – that their actions have been authorized. This is true whether the attack is against your organization or a software product – in the latter case, if you integrate with third-party providers, they should be notified that red teaming may occur.
Once terms are agreed upon, and a goal has been defined, the red team process can begin. This includes:
- A reconnaissance phase to gather as much information as possible about the target. To make the attack as realistic as possible, the red team should not benefit from insider knowledge that would not be available to a likely attacker. However, they can use any means at their disposal to gather intelligence – from reviewing web and press content, satellite images, and social media posts to covert observation or tricking employees into unguarded conversations.
- A planning phase to determine the best tactics, techniques, and procedures to use, together with contingency plans. In the case of an attack on your organization, this might include using social engineering to get an employee to connect a USB drive to a networked device or simply getting close enough to use office Wi-Fi with weak credentials and broad permissions.
- The attack phase. This is when the red team puts their plan into practice. Depending on tactics, this could last for hours to days or weeks. The security team should be operating as usual.
- The attack phase ends when either the red team achieves their goal or is detected and stopped. The point at which the red team reveals themselves by presenting their letter of authority or calling in the senior stakeholder to vouch for them can vary. In some situations, it’s helpful to allow some of the security response to play out as if it were an actual attack, to derive as much learning as possible from the test.
- A report and retrospective phase to provide feedback on the exercise. The report should include complete details of the attack, including those defenses that worked well and those that were breached, what techniques were used to move laterally and/or escalate privileges, and any additional harm that could have been done beyond the defined goal.
Once the process is complete, it’s over to the security team or software developers to start addressing vulnerabilities and updating procedures, ready for the next attack.
Common red teaming tools
If you’re new to red teaming, various tools can help you get the most value out of this security testing activity.
The MITRE ATT&CK framework is a valuable resource for recording and analyzing the phases of an attack. As a red team, you can use the framework to identify strategies and document your approach for reporting after the event. As a Blue Team, identifying the tactics, techniques, and procedures used in an attack will assist you in identifying mitigations better to protect your organization or your software in the future.
MITRE Caldera is an open-source project from the creators of the ATT&CK framework, which you can use to automate elements of both a red team attack and a Blue Team response.
Finally, tools such as Vectr assist with planning and reporting on red teaming activities, including collecting metrics to assist you in measuring the performance of your defenses.
Conclusion
Red teaming provides the most realistic test of your systems’ and your organization’s defenses against a cyber attack. If your organization is responsible for user data or relies on software systems for day-to-day running, you’re vulnerable to ransomware and data exfiltration attacks. If you’re developing software, verifying the security of your products and services is essential to protect your users from attacks that exploit your system. To get the most out of red teaming, make it an ongoing practice and ensure all findings are shared and acted upon.

